Amazon Aurora
1. Introduction
Amazon Aurora is a fully managed, cloud‐native relational database engine that’s part of Amazon RDS. Designed to deliver the performance and availability of high‑end commercial databases at one‑tenth the cost, Aurora is available in two fully compatible editions – one that is MySQL‑compatible and another that is PostgreSQL‑compatible. It automates time‑consuming database tasks such as provisioning, patching, backup, recovery, and scaling while offering enterprise‑grade security, reliability, and performance.
Aurora is part of the managed database service Amazon Relational Database Service (Amazon RDS). Amazon RDS makes it easier to set up, operate, and scale a relational database in the cloud.
2. How Amazon Aurora works with Amazon RDS
The following points illustrate how Amazon Aurora relates to the standard MySQL and PostgreSQL engines available in Amazon RDS:
-
You choose Aurora MySQL or Aurora PostgreSQL as the DB engine option when setting up new database servers through Amazon RDS.
-
Aurora takes advantage of the familiar Amazon Relational Database Service (Amazon RDS) features for management and administration. Aurora uses the Amazon RDS AWS Management Console interface, AWS CLI commands, and API operations to handle routine database tasks such as provisioning, patching, backup, recovery, failure detection, and repair.
-
Aurora management operations typically involve entire clusters of database servers that are synchronized through replication, instead of individual database instances. The automatic clustering, replication, and storage allocation make it simple and cost-effective to set up, operate, and scale your largest MySQL and PostgreSQL deployments.
-
You can bring data from Amazon RDS for MySQL and Amazon RDS for PostgreSQL into Aurora by creating and restoring snapshots, or by setting up one-way replication. You can use push-button migration tools to convert your existing RDS for MySQL and RDS for PostgreSQL applications to Aurora.
3. Amazon Aurora DB clusters
An Amazon Aurora DB cluster consists of one or more DB instances and a cluster volume that manages the data for those DB instances. An Aurora cluster volume is a virtual database storage volume that spans multiple Availability Zones, with each Availability Zone having a copy of the DB cluster data. Two types of DB instances make up an Aurora DB cluster:
-
Primary (writer) DB instance: Supports read and write operations, and performs all of the data modifications to the cluster volume. Each Aurora DB cluster has one primary DB instance.
-
Aurora Replica (reader DB instance): Connects to the same storage volume as the primary DB instance but supports only read operations. Each Aurora DB cluster can have up to 15 Aurora Replicas in addition to the primary DB instance. Maintain high availability by locating Aurora Replicas in separate Availability Zones. Aurora automatically fails over to an Aurora Replica in case the primary DB instance becomes unavailable. You can specify the failover priority for Aurora Replicas. Aurora Replicas can also offload read workloads from the primary DB instance.
The following diagram illustrates the relationship between the cluster volume, the writer DB instance, and reader DB instances in an Aurora DB cluster.
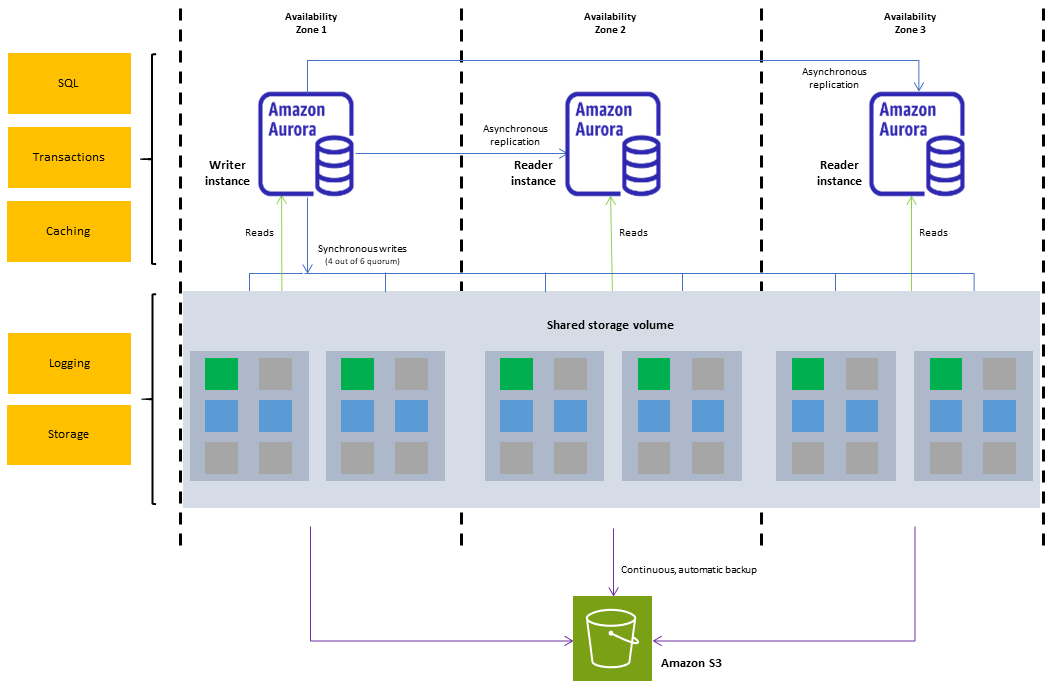
The Aurora DB cluster illustrates the separation of compute capacity and storage. For example, an Aurora configuration with only a single DB instance is still a cluster, because the underlying storage volume involves multiple storage nodes distributed across multiple Availability Zones (AZs).
4. Blue/Green Deployments
A blue/green deployment copies a production database environment in a separate, synchronized staging environment. By using Amazon RDS Blue/Green Deployments, you can make changes to the database in the staging environment without affecting the production environment. For example, you can upgrade the major or minor DB engine version, change database parameters, or make schema changes in the staging environment. When you are ready, you can promote the staging environment to be the new production database environment. For more information, see Using Amazon Aurora Blue/Green Deployments for database updates.
5. DB Cluster Storage Configurations
Amazon Aurora has two DB cluster storage configurations, Aurora I/O-Optimized and Aurora Standard.
-
Aurora I/O-Optimized Improved price performance and predictability for I/O-intensive applications. You pay only for the usage and storage of your DB clusters, with no additional charges for read and write I/O operations. Aurora I/O-Optimized is the best choice when your I/O spending is 25% or more of your total Aurora database spending.
You can choose Aurora I/O-Optimized when you create or modify a DB cluster with a DB engine version that supports the Aurora I/O-Optimized cluster configuration. You can switch from Aurora I/O-Optimized to Aurora Standard at any time.
-
Aurora Standard: Cost-effective pricing for many applications with moderate I/O usage. In addition to the usage and storage of your DB clusters, you also pay a standard rate per 1 million requests for I/O operations.
Aurora Standard is the best choice when your I/O spending is less than 25% of your total Aurora database spending.
You can switch from Aurora Standard to Aurora I/O-Optimized once every 30 days. When you switch between Aurora Standard and Aurora I/O-Optimized storage options for non-NVMe-based DB instances, there is no downtime. However, for NVMe-based DB instances, switching between Aurora I/O-Optimized and Aurora Standard storage options requires a database engine restart, which may cause a brief period of downtime.
6. Database Activity Streams
Database Activity Streams capture a near‑real‑time, immutable stream of database operations (SQL queries, DML, DDL, etc.) for auditing, compliance, and security analysis.
When enabled, Aurora streams activity logs from the database to a secure destination (such as Amazon Kinesis or third‑party SIEM solutions) without affecting the performance of your production workload.
7. Backing up and restoring an Amazon Aurora DB cluster
Aurora backs up your cluster volume automatically and retains restore data for the length of the backup retention period. Aurora automated backups are continuous and incremental, so you can quickly restore to any point within the backup retention period. No performance impact or interruption of database service occurs as backup data is being written. You can specify a backup retention period from 1–35 days when you create or modify a DB cluster. Aurora automated backups are stored in Amazon S3.
If you want to retain data beyond the backup retention period, you can take a snapshot of the data in your cluster volume. Aurora DB cluster snapshots don't expire. You can create a new DB cluster from the snapshot.
7.1. Using AWS Backup
You can use AWS Backup to manage backups of Amazon Aurora DB clusters.
Snapshots managed by AWS Backup are considered manual DB cluster snapshots, but don't count toward the DB cluster snapshot quota for Aurora. Snapshots that were created with AWS Backup have names with awsbackup:job-`AWS-Backup-job-number` .
You can also use AWS Backup to manage automated backups of Amazon Aurora DB clusters. If your DB cluster is associated with a backup plan in AWS Backup, you can use that backup plan for point-in-time recovery. Automated (continuous) backups that are managed by AWS Backup have names with continuous:cluster-`AWS-Backup-job-number` .
7.2. Backup Window
Automated backups occur daily during the preferred backup window. If the backup requires more time than allotted to the backup window, the backup continues after the window ends, until it finishes. The backup window can't overlap with the weekly maintenance window for the DB cluster.
7.3. Restoring Data
You can recover your data by creating a new Aurora DB cluster from the backup data that Aurora retains, from a DB cluster snapshot that you have saved, or from a retained automated backup. You can quickly restore a new copy of a DB cluster created from backup data to any point in time during your backup retention period. Because Aurora backups are continuous and incremental during the backup retention period, you don't need to take frequent snapshots of your data to improve restore times.
The latest restorable time for a DB cluster is the most recent point to which you can restore your DB cluster. This is typically within 5 minutes of the current time for an active DB cluster, or 5 minutes of the cluster deletion time for a retained automated backup.
The earliest restorable time specifies how far back within the backup retention period that you can restore your cluster volume.
To determine the latest or earliest restorable time for a DB cluster, look for the Latest restorable time or Earliest restorable time values on the RDS console.
7.4. Database Cloning for Aurora
By using Aurora cloning, you can create a new cluster that initially shares the same data pages as the original, but is a separate and independent volume. The process is designed to be fast and cost-effective. The new cluster with its associated data volume is known as a clone. Creating a clone is faster and more space-efficient than physically copying the data using other techniques, such as restoring a snapshot.
Aurora uses a copy-on-write protocol to create a clone. This mechanism uses minimal additional space to create an initial clone. When the clone is first created, Aurora keeps a single copy of the data that is used by the source Aurora DB cluster and the new (cloned) Aurora DB cluster. Additional storage is allocated only when changes are made to data (on the Aurora storage volume) by the source Aurora DB cluster or the Aurora DB cluster clone.
8. Exporting Cluster and Snapshot data to Amazon S3
This feature enables you to export data directly from an Aurora cluster to Amazon S3—typically in a columnar format like Parquet. Once in S3, the data can be queried by services such as Amazon Athena or loaded into Amazon Redshift for analytical processing.
The export operation is designed to have minimal impact on the cluster’s performance and is useful for integrating with big‑data analytics workflows.
If you don't specify a preferred backup window when you create the DB cluster, Aurora assigns a default 30-minute backup window. This window is selected at random from an 8-hour block of time for each AWS Region.
8.1. Exporting Snapshot Data to Amazon S3
Similar to exporting cluster data, this feature lets you export the data contained in a database snapshot to Amazon S3. Snapshot exports enable you to analyze historical data without impacting the live database.
Storing data in S3 (often in efficient formats) can be more economical than keeping all historical data online.
When you export a snapshot, Aurora converts the snapshot data into a format optimized for query performance (like Parquet), which you can then process or analyze using other AWS services.
9. Aurora Global Databases
With the Amazon Aurora Global Database feature, you set up multiple Aurora DB clusters that span multiple AWS Regions. Aurora automatically synchronizes all changes made in the primary DB cluster to one or more secondary clusters. An Aurora global database has a primary DB cluster in one Region, and up to five secondary DB clusters in different Regions. This multi-Region configuration provides fast recovery from the rare outage that might affect an entire AWS Region. Having a full copy of all your data in multiple geographic locations also enables low-latency read operations for applications that connect from widely separated locations around the world.
In the following diagram, you can find an example Aurora global database that spans two AWS Regions.
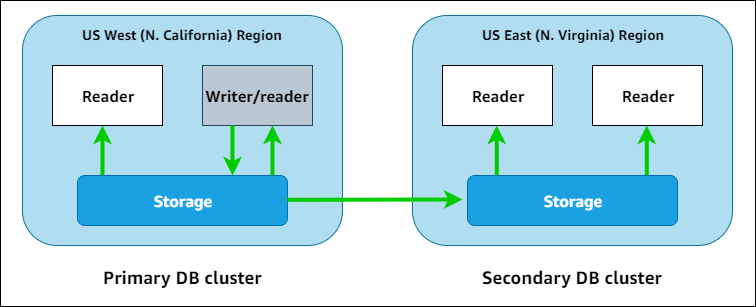
Why It Matters:
- Global Read Scalability: Users around the world can access low‑latency reads by connecting to a nearby region.
- Disaster Recovery: In case of a regional outage, one of the secondary regions can be promoted to primary within minutes, ensuring business continuity.
- Strong Consistency: Replication is done with typical latencies of less than one second, maintaining strong consistency across regions.
Aurora Global Database uses dedicated infrastructure for replication so that adding secondary regions does not affect the performance of your primary cluster.
10. IAM Database Authentication
IAM database authentication allows you to connect to Aurora using AWS Identity and Access Management (IAM) credentials instead of a static password. Once enabled, your application can use an IAM authentication token (generated by the AWS SDK or CLI) to establish a secure connection with Aurora.
11. Kerberos Authentication
Aurora supports Kerberos authentication, allowing integration with enterprise identity management systems (like Active Directory). Kerberos authentication in Aurora works alongside IAM and other security features to provide a robust and flexible authentication framework.
12. Aurora Machine Learning
By using Amazon Aurora machine learning, you can integrate your Aurora DB cluster with one of the following AWS machine learning services, depending on your needs. They each support specific machine learning use cases.
Amazon Bedrock is a fully managed service that makes leading foundation models from AI companies available through an API, along with developer tooling to help build and scale generative AI applications.
Amazon Comprehend is a natural language processing (NLP) service that's used to extract insights from documents. By using Aurora machine learning with Amazon Comprehend, you can determine the sentiment of text in your database tables.
SageMaker AI is a full-featured machine learning service. Data scientists use Amazon SageMaker AI to build, train, and test machine learning models for a variety of inference tasks, such as fraud detection. By using Aurora machine learning with SageMaker AI, database developers can invoke the SageMaker AI functionality in SQL code.
13. Performance Insights
Performance Insights expands on existing Amazon RDS monitoring features to illustrate and help you analyze your database performance. With the Performance Insights dashboard, you can visualize the database load on your Amazon RDS DB instance load and filter the load by waits, SQL statements, hosts, or users.
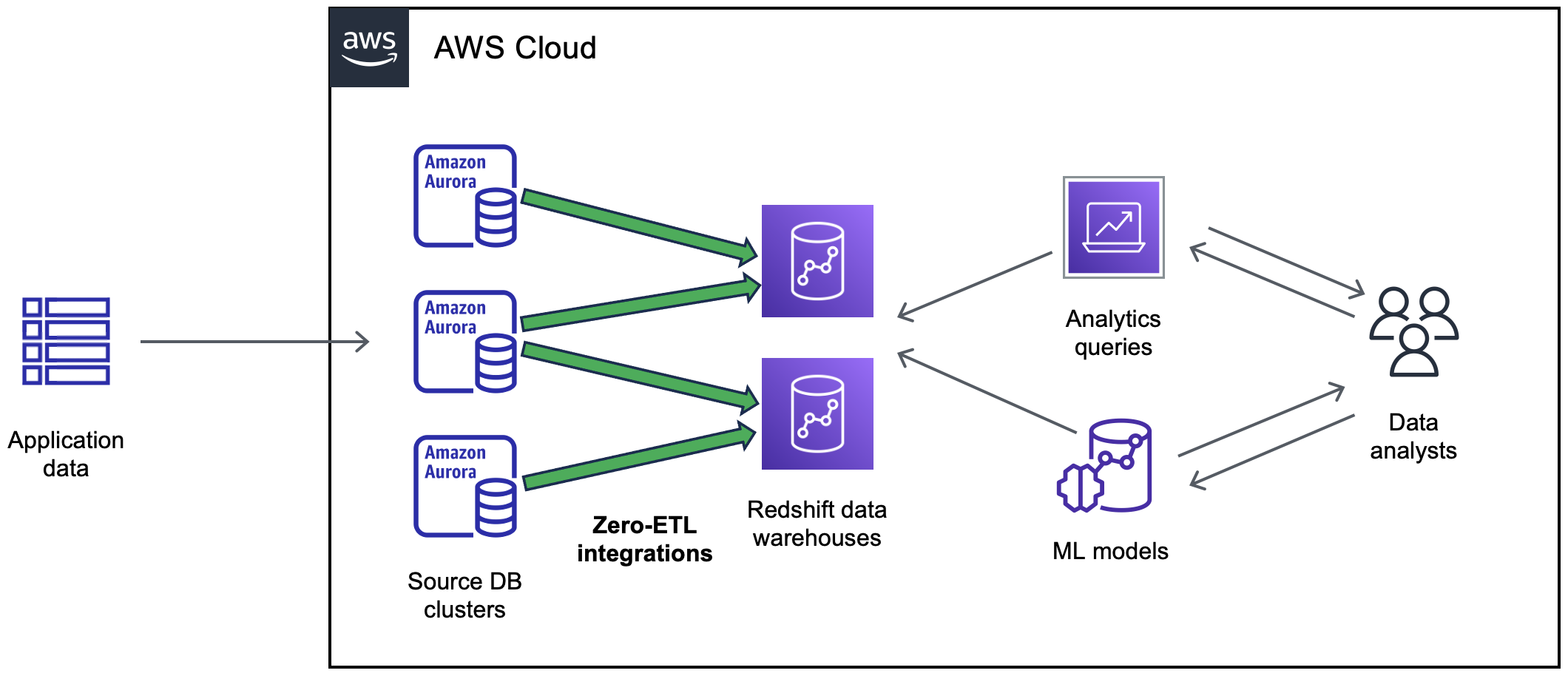
14. Zero‑ETL Integrations
Zero‑ETL integration enables seamless, near‑real‑time movement of transactional data from Aurora to data warehouses like Amazon Redshift without the need for traditional extract, transform, and load (ETL) processes. Aurora continuously replicates changes to a target Redshift cluster so that you can run analytical queries directly against the replicated data.
15. RDS Proxy
RDS Proxy is a fully managed database proxy that sits between your application and Aurora, pooling and sharing connections to improve scalability and application resiliency. It reduces the overhead of opening and closing connections, particularly beneficial for serverless or microservices architectures.
Using RDS Proxy, you can handle unpredictable surges in database traffic. Otherwise, these surges might cause issues due to oversubscribing connections or new connections being created at a fast rate. RDS Proxy establishes a database connection pool and reuses connections in this pool. This approach avoids the memory and CPU overhead of opening a new database connection each time. To protect a database against oversubscription, you can control the number of database connections that are created.
RDS Proxy queues or throttles application connections that can't be served immediately from the connection pool. Although latencies might increase, your application can continue to scale without abruptly failing or overwhelming the database. If connection requests exceed the limits you specify, RDS Proxy rejects application connections (that is, it sheds load). At the same time, it maintains predictable performance for the load that RDS can serve with the available capacity.
RDS Proxy minimizes downtime during failovers and improves overall performance by reducing the connection churn on your Aurora instances.
16. Secrets Manager Integration
Aurora integrates with AWS Secrets Manager to store and manage your database credentials, API keys, and other secrets. Secrets Manager can automatically rotate secrets, reducing the risk of compromised credentials.
Aurora can automatically retrieve the latest credentials from Secrets Manager when establishing a connection, streamlining secure access.
17. Aurora Serverless v2
Aurora Serverless v2 is an on-demand, autoscaling configuration for Amazon Aurora. Aurora Serverless v2 helps to automate the processes of monitoring the workload and adjusting the capacity for your databases. Capacity is adjusted automatically based on application demand. You're charged only for the resources that your DB clusters consume. Thus, Aurora Serverless v2 can help you to stay within budget and avoid paying for computer resources that you don't use.
This type of automation is especially valuable for multitenant databases, distributed databases, development and test systems, and other environments with highly variable and unpredictable workloads.
In summary, its use cases include:
-
Unpredictable or Variable Workloads:
Ideal for applications where traffic patterns are hard to predict—such as new applications, development/testing environments, or seasonal demand—ensuring that the database scales up or down instantly as needed. -
Cost-Effective Scaling:
It helps reduce costs for workloads that are intermittent or have sporadic spikes by charging per second of actual usage rather than provisioning for peak capacity all the time. -
High-Throughput, Low-Latency Applications:
With instant, fine-grained scaling, it supports production workloads that require quick responses during traffic surges without downtime, making it suitable for modern web and mobile applications. -
Mixed-Configuration Clusters:
Aurora Serverless v2 can be integrated with provisioned instances within the same cluster, offering flexibility when parts of your workload are constant while others are variable.
This combination of elasticity, cost efficiency, and full Aurora functionality makes Serverless v2 a great choice for both new and existing applications with variable demand.
18. RDS Data API
The RDS Data API provides a simple, secure HTTP‑based interface to interact with Aurora Serverless databases without needing persistent connections or native database drivers.
Why It Matters:
- Ease of Use: Ideal for web and serverless applications where maintaining a persistent connection is challenging.
- Security: Uses HTTPS to securely execute SQL statements and retrieve results.
- Simplified Integration: Eliminates the need for connection pooling or managing database drivers in your code.
You send SQL commands via an HTTP request, and the API returns the results, allowing you to integrate database operations into your applications using standard web protocols.
19. Zero‑Downtime Patching (ZDP)
Zero‑Downtime Patching (ZDP) allows you to apply security patches and updates to your Aurora database engine without incurring downtime.
Why It Matters:
- Continuous Availability: Updates are applied in a rolling fashion or via live patching so that the database remains online.
- Security: Ensures that your database can be updated promptly without disrupting operations.
- Operational Efficiency: Minimizes the maintenance window and reduces risk during updates.
ZDP leverages techniques such as rolling updates and failover coordination to patch instances individually while keeping the overall cluster available.
20. Engine‑Native Features for Aurora MySQL
20.1. Advanced Auditing
A built‑in auditing capability that logs detailed database activities such as DML, DDL, and user actions. It helps meet compliance and security requirements by capturing comprehensive audit logs without needing third‑party tools. Administrators can configure the level of detail captured, and the logs can be streamed to secure destinations for further analysis.
20.2. Backtrack
A feature that allows you to “rewind” an Aurora MySQL cluster to a specific point in time without restoring from a backup. It offers rapid recovery from user errors (for example, accidental data deletions or misconfigured queries) by reverting the cluster state quickly. Aurora continuously maintains a history of changes (for a user‑specified retention window), enabling a nearly instantaneous rollback to a chosen time.
20.3. Fault Injection Queries
A testing tool that lets you deliberately inject errors or simulate failure scenarios into the database. It enables developers and DBAs to validate the resilience and recovery mechanisms of their applications and database configurations. By running specific fault injection queries, you can simulate latency, error conditions, or other faults, then observe how the system and your applications respond.
20.4. In‑Cluster Write Forwarding
A mechanism that allows Aurora Replicas to forward write queries to the primary writer when needed. This helps maintain strong consistency and reduces application complexity by ensuring that write‐intensive queries executed on replicas are automatically redirected to the primary. When a write request is issued against a replica (perhaps inadvertently), the system automatically routes it to the primary instance so that the write is applied correctly.
20.5. Parallel Query
A performance‑enhancing feature that offloads parts of query processing (like filtering and aggregation) directly to the storage layer. It speeds up complex analytical queries on large datasets without burdening the database compute layer. The storage layer processes parts of the query in parallel across its distributed nodes, reducing the amount of data transferred and accelerating query execution.
21. Engine‑Native Features for Aurora PostgreSQL
21.1. Babelfish
A compatibility layer that enables Aurora PostgreSQL to understand T‑SQL commands and the SQL Server wire protocol. It allows applications originally developed for Microsoft SQL Server to run on Aurora PostgreSQL with minimal code changes, simplifying migrations. Babelfish translates T‑SQL queries into PostgreSQL‑compatible SQL, effectively bridging the gap between the two environments.
21.2. Fault Injection Queries (PostgreSQL)
Similar to the MySQL variant, this feature lets you simulate faults within the Aurora PostgreSQL engine. It provides a controlled environment for testing the database’s behavior under failure conditions, ensuring that error handling and recovery are robust. Specific queries trigger simulated faults or delays, enabling you to observe and optimize the system’s response to adverse conditions.
21.3. Query Plan Management
A set of tools and capabilities that allow DBAs to capture, analyze, and enforce stable query execution plans. It mitigates performance variability caused by changes in execution plans—ensuring consistent performance even as data or system conditions evolve. DBAs can “freeze” a preferred execution plan for critical queries or adjust plan settings so that the query optimizer uses a known, efficient plan over time.
22. Aurora Endpoints
Aurora endpoints abstract the complexity of connecting to a database cluster that consists of multiple DB instances (a primary for writes and one or more replicas for reads). This abstraction eliminates the need for applications to track individual instance hostnames, simplifies connection management, and ensures that connections are automatically re-routed in the event of failover.
22.1. Cluster Endpoint
- Usage:
Connects to the primary (writer) instance in an Aurora cluster for read/write operations. - Behavior:
If the primary instance fails and a replica is promoted, the cluster endpoint automatically points to the new primary.
22.2. Reader Endpoint
- Usage:
Balances read-only queries among all Aurora Replicas. - Behavior:
Aurora manages load balancing and automatically directs connections to available replicas, improving read scalability.
22.3. Instance Endpoint
- Usage:
Connects directly to a specific DB instance (primary or replica) for detailed monitoring, troubleshooting, or performance tuning. - Behavior:
Unlike cluster or reader endpoints, instance endpoints do not automatically change during failover, so they are typically used for diagnostic purposes.
22.4. Custom Endpoint
- Usage:
Enables you to define your own endpoints that route connections to specific subsets of DB instances based on instance type or configuration. - Behavior:
Useful when your cluster contains instances with different capacities or roles and you want to isolate workloads accordingly.
22.5. Aurora Global Database Writer Endpoint
- Usage:
In an Aurora Global Database setup, this special endpoint functions like a cluster endpoint for the primary region. - Behavior:
It automatically updates to point to the new primary if a failover occurs in a multi-region deployment, simplifying cross-region connection management.
23. Migration and Cost Benefits
Aurora was designed to be a drop‑in replacement for MySQL and PostgreSQL. With high compatibility, most existing tools and applications can migrate with minimal changes using native dump/restore tools, snapshots, or AWS DMS. Aurora’s cost model is based on usage (for serverless) or on‑demand/reserved instances, and because you only pay for one copy of your data (even though it is replicated across multiple AZs), overall costs are kept very competitive compared to commercial databases.
24. Conclusion
Amazon Aurora is a next‑generation, cloud‑optimized relational database service that redefines high performance, availability, and cost‑efficiency. Its innovative architecture, comprehensive feature set, and seamless integration with other AWS services make it an ideal choice for modern, globally distributed, and mission‑critical applications.
For the most authoritative and detailed information, please consult the official AWS documentation.