Kinesis Data Firehose
1. Introduction
Amazon Kinesis Data Firehose is a fully managed service designed to reliably capture, transform, and load streaming data into various destinations. It automatically scales to accommodate varying data throughputs and employs a buffering mechanism to batch records, enabling near real-time delivery. With built-in support for optional data transformations via AWS Lambda, robust backup options, and seamless integration with key AWS services, Kinesis Data Firehose is an ideal choice for modern data ingestion pipelines—from real-time analytics to data lake formation.
2. Core Concepts and Key Features
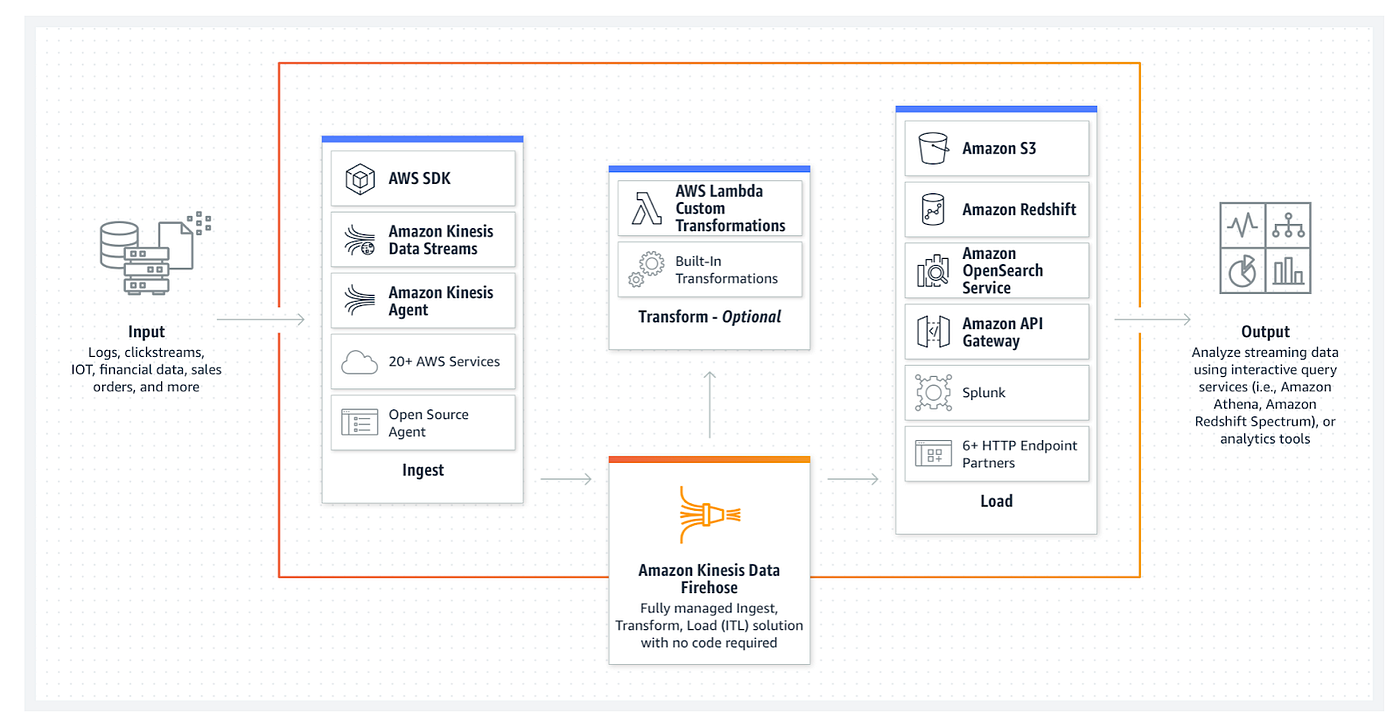
Kinesis Data Firehose continuously captures streaming data from diverse producers—whether directly from applications, IoT devices, or even from Kinesis Data Streams—and delivers it to target destinations such as:
- Amazon S3
- Amazon Redshift (via an intermediate storage mechanism)
- Amazon OpenSearch Service (formerly Elasticsearch Service)
- Splunk
In addition, Firehose supports integrations with partner applications (e.g., Datadog, MongoDB) and custom HTTPS endpoints. Its core functionality revolves around:
- Automatic Scaling: Eliminates the need for manual provisioning or shard management.
- Buffering: Uses configurable buffer size (in MB) and buffer interval (in seconds) settings to accumulate data before delivery.
- Optional Data Transformation: Leverages AWS Lambda to convert, filter, or enrich data on the fly.
- Backup Mechanisms: Offers options to back up all incoming or only failed records to an Amazon S3 bucket, ensuring no data is lost.
- Monitoring & Security: Integrates with Amazon CloudWatch for real-time metrics and supports encryption (both in transit and at rest) through AWS KMS and TLS.
For a complete official overview, refer to the Amazon Kinesis Data Firehose overview page and the Developer Guide.
3. Data Flow and Buffering Mechanism
3.1. Data Ingestion and Flow
Data flows into Kinesis Data Firehose either directly from producers (such as applications and connected devices) or indirectly from other streaming services like Kinesis Data Streams. Once received, data is buffered to optimize delivery:
- Buffer Size (in MB): Once the cumulative size of the buffered data reaches the specified limit, Firehose automatically flushes and delivers the batch.
- Buffer Interval (in seconds): If the data does not reach the size threshold within the defined time window, the accumulated data is flushed once the time elapses.
This dual-parameter buffering mechanism ensures that Firehose can efficiently handle both high-traffic and low-traffic scenarios while maintaining near real-time delivery.
3.2. Data Transformation and Backup
Before delivery, Firehose can optionally invoke an AWS Lambda function to perform transformations—such as converting CSV to JSON or filtering unnecessary information. If transformation fails or if delivery to the primary destination (e.g., Amazon S3, Redshift, OpenSearch, or Splunk) cannot proceed, Firehose can automatically back up either all source records or only the failed records to a designated S3 bucket. This feature provides data traceability and loss prevention.
4. Security, Monitoring, and Pricing
4.1. Security and Compliance
Kinesis Data Firehose is designed with enterprise-grade security features:
- Access Control: Utilizes AWS Identity and Access Management (IAM) for fine-grained permissions.
- Encryption: Supports encryption at rest (via AWS KMS) and in transit (using TLS), ensuring data integrity and compliance with regulatory standards.
- Auditability: The backup of source or failed records to Amazon S3 aids in compliance and auditing processes.
4.2. Monitoring and Logging
Firehose is tightly integrated with Amazon CloudWatch, enabling you to:
- Track Delivery Metrics: Monitor throughput, latency, and success/failure rates.
- Set Alerts: Configure CloudWatch alarms to notify you of anomalies or performance issues.
- Troubleshoot Issues: Use detailed logs to diagnose delivery problems or transformation failures.
4.3. Pricing
Kinesis Data Firehose follows a pay-as-you-go pricing model, where charges are based on the volume of data ingested and processed. There is no additional cost for scaling or shard management. Optional AWS Lambda transformation incurs additional costs based on execution time and resource consumption.
For up-to-date pricing details, refer to the AWS Kinesis Data Firehose Pricing page
5. Getting Started and Best Practices
To begin using Kinesis Data Firehose:
- Setup: Create and configure a Firehose delivery stream via the AWS Management Console, AWS CLI, or AWS SDKs.
- Configuration: Adjust buffer size and interval settings to match your expected data throughput, and configure Lambda transformations if needed.
- Validation: Test your configuration with sample data to ensure that the data is transformed and delivered correctly.
- Monitoring: Regularly review CloudWatch metrics and logs to maintain high performance and to troubleshoot any issues promptly.
The simplicity and scalability of Firehose make it a favored choice for streaming data ingestion into data lakes and analytics platforms.
6. Comparison: Kinesis Data Firehose vs. Kinesis Data Streams
While both services are built to handle streaming data, they cater to different use cases and operational models:
| Feature | Kinesis Data Streams (KDS) | Kinesis Data Firehose |
|---|---|---|
| Real-Time Processing | Low-latency reads (tenths of a second) | Near real-time delivery with buffering (seconds to minutes) |
| Scaling & Management | Manual provisioning and scaling via shards | Fully managed, auto-scaling |
| Data Retention | Stores data for 1-365 days | No storage - data flows directly to destination |
| Replay Capability | Supports multiple replays | No replay capability |
| Consumer Support | Multiple concurrent consumers (Spark, KCL, etc.) | Single pipeline to destination |
| Data Transformation | Requires external processing | Built-in Lambda transformation support |
| Cost Structure | Per-shard pricing + data volume | Pay-per-use based on data volume |
| Framework Support | Works with Spark Streaming, Kinesis Client Library | Not compatible with stream processing frameworks |
| Operational Overhead | Higher (requires shard management) | Serverless - minimal administration |
7. Conclusion
Kinesis Data Firehose offers a powerful, fully managed solution for delivering streaming data into various AWS destinations with minimal operational overhead. Its robust buffering, transformation, and backup capabilities ensure reliable, near real-time data delivery, making it an indispensable tool for modern analytics, IoT, and data lake applications.
By merging official AWS documentation with detailed architectural insights and practical comparisons with Kinesis Data Streams, this chapter provides a comprehensive understanding of how Firehose simplifies data ingestion and processing while maintaining high standards of security, scalability, and performance.
For further reading and the most current details, consult the Amazon Kinesis Data Firehose Developer Guide and the AWS product overview.